eHealth Knowledge Discovery in Spanish¶
Natural Language Processing (NLP) methods are increasingly being used to mine knowledge from unstructured health texts. Recent advances in health text processing techniques are encouraging researchers and health domain experts to go beyond just reading the information included in published texts (e.g. academic manuscripts, clinical reports, etc.) and structured questionnaires, to discover new knowledge by mining health contents. This has allowed other perspectives to surface that were not previously available.
Over the years many eHealth challenges have taken place, which have attempted to identify, classify, extract and link knowledge, such as Semevals, CLEF campaigns and others.
The eHealth-KD 2020 proposes --as the previous editions eHealth-KD 2019 and eHealth-KD 2018-- modeling the human language in a scenario in which Spanish electronic health documents could be machine readable from a semantic point of view. With this task, we expect to encourage the development of software technologies to automatically extract a large variety of knowledge from eHealth documents written in the Spanish Language.
Even though this challenge is oriented to the health domain, the structure of the knowledge to be extracted is general-purpose. The semantic structure proposed models four types of information units. Each one represents a specific semantic interpretation, and they make use of thirteen semantic relations among them. The following sections provide a detailed presentation of each unit and relation type. An example is provided in the following picture.
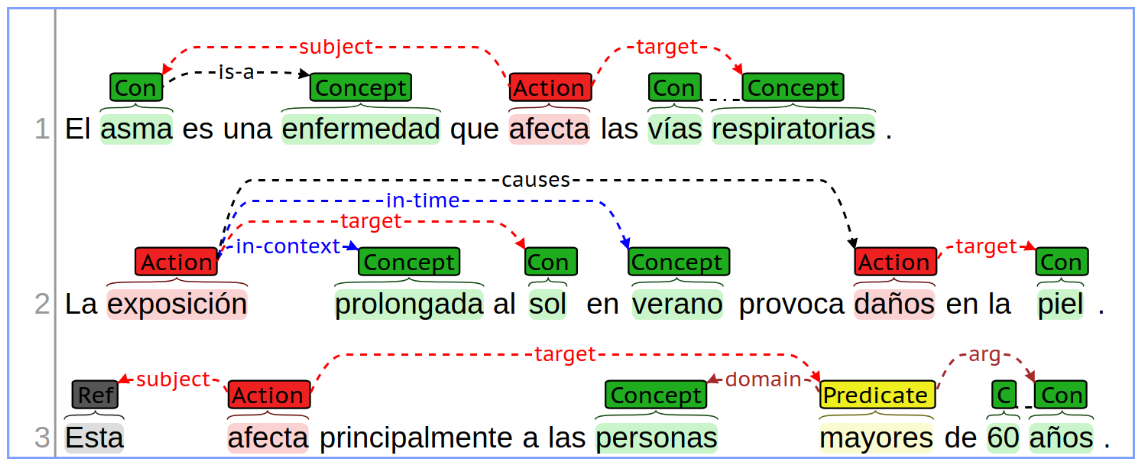
This challenge can be of interest for experts in the field of natural language processing, specifically for those working on automatic knowledge extraction and discovery. It is not a requirement to have expertise in health texts processing for dealing with the eHealth-KD task, due to the general purpose of the semantic schema defined. Nevertheless, eHealth researchers could find interesting this challenge to evaluate their technologies that rely on health domain knowledge.
Latest results¶
These are the latest official results for Scenario 1 in the Test collection.
| Team | Submission | F1 | Precision | Recall |
|---|---|---|---|---|
| baseline | dummy | 0.424 | 0.519 | 0.359 |
| baseline | random | 0.116 | 0.124 | 0.108 |
Check out the detailed results page for more information.
Description of the Subtasks¶
To simplify the evaluation process, two subtasks are presented:
There are four evaluation scenarios:
- A main scenario covering both tasks
- An optional scenario evaluating subtask A
- An optional scenario evaluating subtask B
Submissions and evaluation¶
The challenge will be graded in Codalab.
Resources¶
All data is available for download. This includes training, development and test data, as well as evaluation scripts and sample submissions. More details are provided here.